https://online2.tingclass.net/lesson/shi0529/0008/8146/gg_297.mp3
https://image.tingclass.net/statics/js/2012
Episode 297: October 27, 2011
The podcast edition of this article was sponsored by Audible. Get a free audiobook to keep when you sign up for a free trial at AudiblePodcast.com/gg.
This week Quick and Dirty Tips launched a new podcast called the Tech Talker, so we’re all doing tech-themed topics to show our support, and I’m glad we are because I get to tell you about a new tool from Google Books I’ve been using called the Ngram Viewer that I probably wouldn’t have mentioned otherwise.
What Is the Google Book Corpus?
The Ngram Viewer lets you search the Google Books corpus. In this context, “corpus” is just a fancy word for a collection of writings, but the Google Books corpus might deserve a fancy word because it’s huge. It contains 155 billion words, and the Ngram Viewer lets you search those words, and it makes graphs of how often your search terms appeared over time starting around 1800.
Examples of Results from the Google Ngram Viewer
Among other things, I’ve used it to see that printed materials have been including the word “schadenfreude” more often in recent years, and that “wet your whistle” is much more common in print than “whet your whistle” even though the Oxford English Dictionary lists both options.
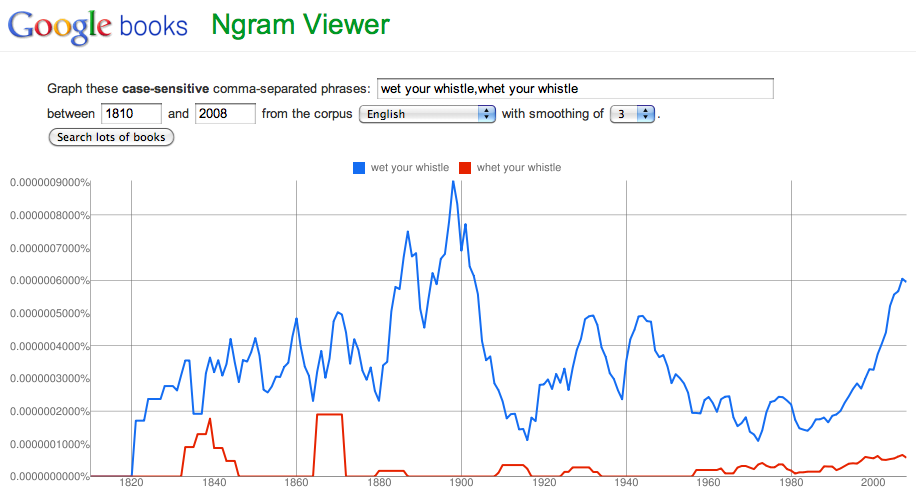
It can be a little addictive once you start playing with it. I find myself thinking, “Well, sure, people say ‘gone missing’ is a new phrase that’s driving them crazy, but is it really so new and is it really increasing?” or “When did ‘graduated college’ start showing up in print instead of ‘graduated from college’?” These questions seem a lot easier to answer once you can search a corpus.
The Google Books corpus is by no means the only corpus on the Web, but from what I’ve seen, it has the simplest interface, which makes it easier for beginners to use. However, its simplicity and the way it was made means that it also has some important limitations.
Limitations of the Ngram Viewer: Language Changes
The first thing to keep in mind while searching is that English has changed a lot since the 1800s. We say things differently than we used to. For example, in the early 1800s they made the phrase “somebody else” possessive differently than we would today. In 1810 you could have talked about “somebody’s else problem” instead of “somebody else’s problem” (1, 2). So be a bit wary of results from long ago; they could be skewed by language changes you don’t know about.
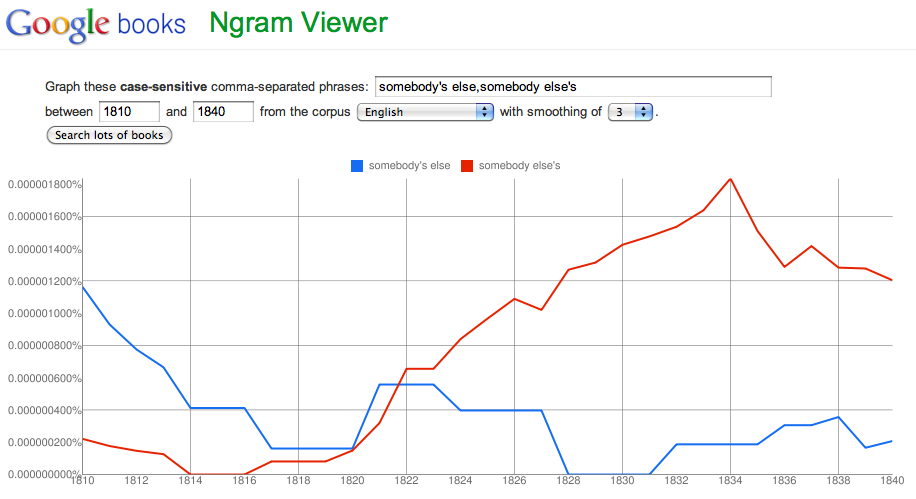
The Ngram Viewer is case sensitive, and nouns were capitalized in English more often in the 1800s than they are today. It’s always a good idea to do your search with the words lowercase and capitalized just to make sure you haven’t missed something.
Limitations of the Ngram Viewer: OCR Errors
The Google Book corpus was created by scanning physical books and then using optical character recognition to create the database of words, but optical character recognition isn’t perfect. For example, on its “About Google Books Ngram Viewer” page, Google notes that the word “Internet” appears in the database in documents older than 1950. It’s not because of time traveling software engineers; it’s because of optical character recognition errors. For that reason, the Ngram Viewer isn’t a reliable way to find the first real instance of a word in print.
Optical character recognition can cause other problems too. For searches in the very early 1800s, you have to take into account the medial s or the long s. Back then printers had two forms of the letter s, and one looks so much like an f that it can be interpreted as an f by today’s software programs. For example, in some old books, “English” will appear to Google Books to be “Englisf.” (The image below is from a 1761 literature journal.)

It’s never made enough of a difference to matter in my searches, but if you’re focusing on the early 1800s, it is something you should know about.
Limitations of the Ngram Viewer: Regional Differences
It’s also important to keep the differences between British English and American English in mind when you’re searching. The default search combines British and American sources, but there’s a pull-down menu that lets you search just one or the other.
Unfortunately, I haven’t been able to find a way to compare British and American usage on the same graph the way you can compare separate phrases. For example, you get a graph of approximately the same shape when you search the British and American databases for the British phrase “Bob’s your uncle” (which means something like “and there you go”), but you have to look carefully at the scale of the two separate graphs to see that phrase is more common in Britain.
Limitations of the Ngram Viewer: Multiple Meanings
Of course, no matter what form of English we’re talking about, we also have words with the same spelling but completely different meanings. For example, make sure that if you want to search about the shore, as in the beach, you use other search terms that will omit the verb “shore,” as in to shore up a position, and that you’re excluding references to the TV show Jersey Shore. For example, a search for the two words “the shore” would be more precise than just “shore” alone.
Limitations of the Ngram Viewer: Historical Events
It doesn’t take long playing with the Ngram Viewer to start stumbling on weird spikes that you suspect you could explain, if only you knew more about history. In 1865 there was a spike in the word “missing” in American English--maybe it’s related to the Civil War?--and between 1941 and 1949 there was a spike in the phrase “went missing”--maybe because of World War II? I’m not sure.
Other events can confound you too, not just wars. I recently wrote a blog post about whether apple cider is redundant because “cider” is defined in some dictionaries as juice from apples. The Ngram Viewer shows that the use of “apple cider” started increasing around 1900, and that seemed to make sense with the Oxford English Dictionary definition, which said that apple cider used to mean fermented juice from some other fruits. But then a commenter on the blog, Victor Steinbok, mentioned laws about apple cider vinegar that went into effect around that time, and (lo and behold!) the graph for “apple cider vinegar” shows a similar pattern to the one for “apple cider” alone is pretty clearly contributing to the change in use that originally looked like it was just about apple cider. Without Victor’s tip about the vinegar controversy, it never would have occurred to me to include “vinegar” in the search.
Limitations of the Ngram Viewer: It’s Not Every Book
Finally, even though it’s 155 billion words, the Google Books corpus doesn’t even come close to including every book ever published and some genres may be disproportionately represented. If that could be a problem for your research, you can choose to search Google’s smaller One Million database, which attempts to compensate for this particular problem.
Other Corpora
Intrigued and want to play with more advanced corpora? A good place to start is at the corpus page of Mark Davies, a linguist at Brigham Young University: http://corpus.byu.edu/. His interfaces allow you do things like search for words that appear near each other but not necessarily next to each other or to limit your search to certain parts of speech, and that’s just the beginning.




















